

AI & Data Privacy: Having your cake and eating it too
Data Privacy and AI
Have Your Cake & Eat It Too
The Need
As we’ve argued earlier in this publication, AI is the only innovation worth worrying about today. Insights for future products and business innovations are often buried within the data businesses already have. Conventional methods of data-analytics are not conducive for discovery as they largely help answer questions that humans can postulate. AI on the other hand, can unearth patterns and outliers that do not fit pre-determined hypotheses.
A well crafted machine learning process can help businesses uncover insights that would otherwise go un-noticed. There is simply no faster way for discovery.
Let us understand this from a real-world example. A California fin-tech startup, focussed on home loans, built an all-digital process to eliminate friction and paperwork. They built a Machine Learning based credit-scoring model, to weed out low-quality applications and to set pricing for others. In doing so, they started analyzing all applications that their ML-model rejected and over time, found correlations with some weather and geographical variables that were not obvious. On further efforts, they realized that they were rejecting several flood and fire zone homes, which were unlikely to be high risk. By adding more environmental data to their ML-model, they quickly created a new scoring model for hazard-zone home loans — creating the industry’s best solution for an ignored market segment. The entire process of discovery to product launch, took less than 1 month! It is highly unlikely to achieve such results otherwise.
Privacy: The Challenge With Consumer Data

Data is the lifeblood of AI, yet many regulations and corporate risk- guidelines hobble the task of the CTO. The main data related AI-challenges include:-
- Confidentiality: e.g. protecting personally identifiable information
- Data Residency Regulations: several countries or companies require data to be kept within geographical or corporate boundaries
- Sector-specific Regulations: e.g. healthcare guidelines such as HIPAA
Here are the emerging ways of having your AI-cake and eating it too.
Suggested Solution — Synthetic Data
This fast-emerging field involves computer generated data, often itself powered by Machine Learning. Examples of pioneer startups include Gretel.ai and Mostly.ai (tabular data to simulate customer information), Synthesis.ai (digital human images with pixel-accuracy) etc.
Gartner estimates that by 2025, roughly 60% of all AI/ML training data will be synthetic.
The earliest adoption at scale is happening in financial services and autonomous driving. If you have paid close attention, to the newer Autonomous Vehicle startups, very few of them are found collecting as much real data as pioneers like Waymo, Nuro did. Why? you guessed it! Simulated synthetic data.
As a practitioner/user, there are several key aspects to bear in mind, while using Synthetic Data
Data quality
This refers to the usefulness of synthetic data for AI/ML modeling, relative to the ground truth data. Any useful synthetic dataset generator would likely incorporate a statistical analysis model, to compare the probability distribution of generated data with ground truth. These analyses are referred to as Synthetic Data Quality Scores. See this as an example. High performance synthetic data systems, incorporate quality as part of their data generation process.
 Source: Gretel.ai
Source: Gretel.ai
Data bias or Fair Synthetic Data
One big advantage of synthetic data is its ability to represent any desired statistical distribution, over all input categories. This is specially useful in use-cases where balanced data sets are not naturally occurring, yet the ML-models are required to comply with certain man-made “fairness standards”. E.g. data for high-risk diseases, or data on minority demographics. the definition of “fairness” is very complex, often situation dependent and out of scope for this article. The only thing to remember here is that synthetic data tools give you unprecedented control over achieving your own desired definition of data “fairness”.
Physics-based:
Synthetic data should comply with the laws of physics and nature. This specifically applies to unstructured, natural-world data such as images, sound etc. For example, generating synthetic aerial photographs should adjust for building heights, parallax, shadows etc. This makes the task of achieving statistical similarity lot easier.
Labeled Synthetic Data:
Any generic method of data generation is truly useful for AI/ML if it can provide labeled datasets — otherwise it still leaves a lot of grunt work for humans to accomplish. For example, popular Generative Adversarial Networks (GAN) based ML models have excellent image generation abilities. However they are rarely used for synthetic data generation as historically, they could not generate labeled synthetic data. Luckily, recent research (2021) is helping to get around those problems. One example is shown below. This method uses StyleGANs to generate images, a few of which are manually labeled, and then used to train another small ML-model (called style interpreter). This new model, in turn, labels the entire synthetic dataset!

Suggested Solution — Federated Learning
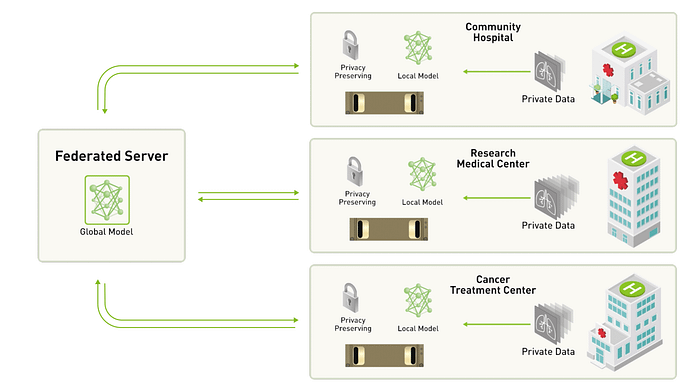
Source: nVidia Corporation
This method employs a unique system architecture that breaks up model training into a Global-Local separated process. Imagine a use-case where you want to train a distributed ML model, to study smartphone user-behavior, by training “Local” models, running locally on each phone. The user-data never leaves their device, but the trained ML parameters are shared with the centralized “Global” process that aggregates the learning across all “Local” devices. This method, while viable, is not very popular.
While we will not go deep into this topic (still in advanced R&D stages), the main issues with FL are related to privacy and data security. Privacy challenges emerge from the fact that in sharing insights from one device to another, some user data or patterns may be inadvertently transferred. There are several methods to reduce this chance, but each comes at a cost of overall accuracy and speed of conversion. For example, “Differential Privacy” is a technique akin to introducing some random noise in the data-sharing process, such that the central hub can never say with certainty which data pattern emerged from which spoke. However these methods will make the overall model less accurate.
In conclusion, I believe that at this time, this is an ongoing research topic and not practical for a most real world applications. It is hard to implement, unless you can control all the Global and Local data devices/locations. Also, it has yet to demonstrate success in training complex and high-accuracy models. It maybe a useful for some low-risk, distributed use-cases such as those on smartphone usage or social media behavior analysis.
Parting Thoughts
What, according to you, are the other ways of addressing data privacy at scale (for AI/ML)? Are there key aspects that I missed in my analysis? What else would you recommend practitioners to consider? I’d love your feedback and critiques.
Reference: Startups worth considering (referred to, in this post)
www.Synthesis.ai
www.Mostly.ai
www.Gretel.ai
www.Rendered.ai
www.Fit.a



https://shorturl.fm/rPvD5
https://shorturl.fm/sfeYq
https://shorturl.fm/xbH4N